출처: http://kr.battle.net/d3/ko/blog/17152343?utm_content=external-sso&utm_medium=other&utm_source=App
시즌 종료: 무엇이 바뀌나요?

네팔렘이여, 때가 다가오고 있습니다. 그 동안 새로운 영웅이 오고 가며 정벌 임무가 완수되었고, 대균열은 정화되었으며 순위표는 영웅들의 이름으로 가득 채워졌습니다.
첫 번째 시즌이 마감되어감에 따라, 이제 어떤 일들이 있어날지 궁금해하시는 분도 많으실 텐데요. 이 블로그를 통해 시즌 1 종료가 여러분께 어떤 영향을 주는 지와 시즌 2를 준비하는 분들을 위해 예상되는 변화를 알려드리고자 합니다.
목차:
앞으로 비시즌 캐릭터로 플레이하면서 만나볼 수 있는 이번 시즌의 모든 보상 목록은 아래에서 확인하실 수 있습니다.
하지만 염려하진 마세요. 시즌이 종료된 이후에도 여러분의 프로필 기록 페이지에선 언제든 여러분의 위대한 흔적을 찾아볼 수 있습니다.

물론 현재와 과거의 순위표는 이 곳 공식 홈페이지에서도 살펴보실 수 있습니다.
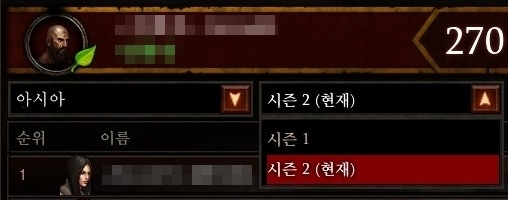 비시즌 대균열 순위표는 시즌 종료에 바로 영향을 받지 않기에 여러분은 계속해서 비시즌 영웅(시즌에서 비시즌으로 전환되는 영웅으로도)으로 순위표 상의 플레이어들과 경쟁할 수 있습니다. 이 대균열 순위표는 시즌 종료 이후에 초기화되며, 여기에 대해서는 추후 세부 정보를 안내해드릴 예정입니다.
비시즌 대균열 순위표는 시즌 종료에 바로 영향을 받지 않기에 여러분은 계속해서 비시즌 영웅(시즌에서 비시즌으로 전환되는 영웅으로도)으로 순위표 상의 플레이어들과 경쟁할 수 있습니다. 이 대균열 순위표는 시즌 종료 이후에 초기화되며, 여기에 대해서는 추후 세부 정보를 안내해드릴 예정입니다.
그럼 언제 시즌1이 종료될까요? 현재 예상하고 있는 가장 이른 시즌 종료 일정은 2015년 2월 3일입니다. (태평양 표준시 기준이며, 정확한 일정은 추후 업데이트 예정) 예기치 못한 문제로 일정은 얼마간 미뤄질 가능성도 있지만, 저희는 최대한 이 일정에 맞춰 시즌을 종료시키려 합니다. 만약 시즌 종료 일정이 변경된다면, 업데이트된 일정을 다시 안내해 드리겠습니다.
댓글로 여러분의 경험담이나 의견을 남겨주세요. 이제 시즌2가 얼마 남지 않았습니다.
첫 번째 시즌이 마감되어감에 따라, 이제 어떤 일들이 있어날지 궁금해하시는 분도 많으실 텐데요. 이 블로그를 통해 시즌 1 종료가 여러분께 어떤 영향을 주는 지와 시즌 2를 준비하는 분들을 위해 예상되는 변화를 알려드리고자 합니다.
목차:
시즌 전환
시즌에 참여한 플레이어분들께서는 익히 아시겠지만 시즌에는 금화, 장비, 정복자 레벨 등 육성하고 획득할 여러 요소들이 있습니다. 그럼 시즌이 종료될 때 이러한 시즌 캐릭터의 진행 정보는 어떻게 되는 것일까요? 간단히 말하자면, 시즌 캐릭터의 진행 정보는 모두 유지할 수 있습니다.앞으로 비시즌 캐릭터로 플레이하면서 만나볼 수 있는 이번 시즌의 모든 보상 목록은 아래에서 확인하실 수 있습니다.
- 영웅
- 시즌 영웅은 비시즌 일반 모드 영웅 및 하드코어 모드 영웅으로 전환됩니다. 해당 영웅을 위한 캐릭터 슬롯을 확보하기 위해 기존의 다른 캐릭터를 삭제할 필요는 없습니다. 현재 시즌 영웅이 차지하고 있는 캐릭터 슬롯은 앞으로도 계속 사용할 수 있으니까요.
- 금화
- 시즌에서 획득한 금화는 비시즌 영웅으로 이전됩니다.
- 정복자 경험치
- 시즌에서 획득한 정복자 레벨의 총합 대신, 획득한 정복자 경험치의 총량이 비시즌으로 이전됩니다.
- 예를 들어, 시즌 영웅의 정복자 레벨이 300 이고 기존 비시즌 영웅의 정복자 레벨이 400 일 경우, 시즌 종료 시 비시즌 영웅의 정복자 레벨은 단순 합산 값인 700 이 아닌 그 이하가 되며, 이는 정복자 레벨이 높아질수록 정복자 레벨이 오르는데 더 많은 경험치가 필요하기 때문입니다.
- 핏빛 파편
- 금화와 비슷하게, 시즌 종료 시점에서 시즌 영웅이 보유한 모든 핏빛 파편은 비시즌 영웅으로 이전됩니다.
- 만약 여러분의 비시즌 영웅들이 현재 핏빛 파편을 최대 보유 한도만큼 지니고 있다면, 시즌 종료시 보유한 시즌 영웅들의 핏빛 파편은 일시적으로 비시즌 영웅들의 최대 보유 한도를 무시하고 이전되어 합산됩니다. 이 핏빛 파편을 여러분이 원하는 대로 소모할 수 있지만, 이렇게 합산된 핏빛 파편의 보유 개수가 최대 보유 한도 이하로 내려가기 전까진 추가로 핏빛 파편을 획득하지 못한다는 점을 유의하시기 바랍니다.
- 아이템
- 현재 시즌 영웅이 착용하고 있거나 소지품에 있는 아이템은 시즌이 종료되면 비시즌 게임 모드로 해당 영웅과 함께 그대로 이전됩니다.
- 시즌 영웅들의 보관함에 있는 아이템은 게임 내 우편 시스템을 통해 비시즌 영웅들에게 보내집니다. 시즌이 종료된 이후 처음으로 게임에 접속한 시점부터 30일간 이러한 아이템을 모든 비시즌 영웅을 통해 수령할 수 있습니다. 우편함을 살펴보시려면 게임을 생성 또는 게임에 참가한 후 화면 좌측 하단에 보이는 우편 아이콘을 누르시면 됩니다.
- 장인 레벨 및 제조법
- 시즌 영웅들의 장인 레벨이 비시즌 영웅들의 장인 레벨 보다 높다면, 시즌 종료 시 해당 장인 레벨이 비시즌 영웅들의 장인 레벨로 이전됩니다.
- 비시즌 장인들이 익히지 못한 시즌 장인의 모든 제조법도 마찬가지로 시즌 종료시 비시즌 장인들에게 이전됩니다.
- 보관함
- 시즌 중에 구매한 공유 보관함 또는 보관함 탭 중 비시즌 영웅들이 보유하지 못한 것은 위와 마찬가지로 비시즌 영웅들에게 이전되어 적용됩니다.
- 업적
- 시즌에서 획득한 업적이나 기록중인 업적 진행 정보는 비시즌 업적 프로필에 자동으로 반영됩니다. 이 작업은 실시간으로 이뤄지며 시즌 종료가 필요한 것은 아닙니다. 업적 점수 또한 시즌 기간 중에 달성한 내역에 맞춰 업데이트됩니다.
- 시즌 1 보상
- 시즌 전용 보상인 투구와 어깨와 부위 형상변환은 시즌 1에서 70레벨 영웅을 육성한 모든 플레이어분들에게 개방됩니다. 시즌 영웅이 70레벨에 도달하는 즉시 이 형상변환이 개방되고, 시즌이 종료되기 전에도 시즌과 비시즌 영웅 모두 이 형상변환을 이용할 수 있습니다. 새로운 형상변환을 이용하시려면, 마을의 미리암을 방문하여 형상변환 탭 창을 열어보시기 바랍니다.
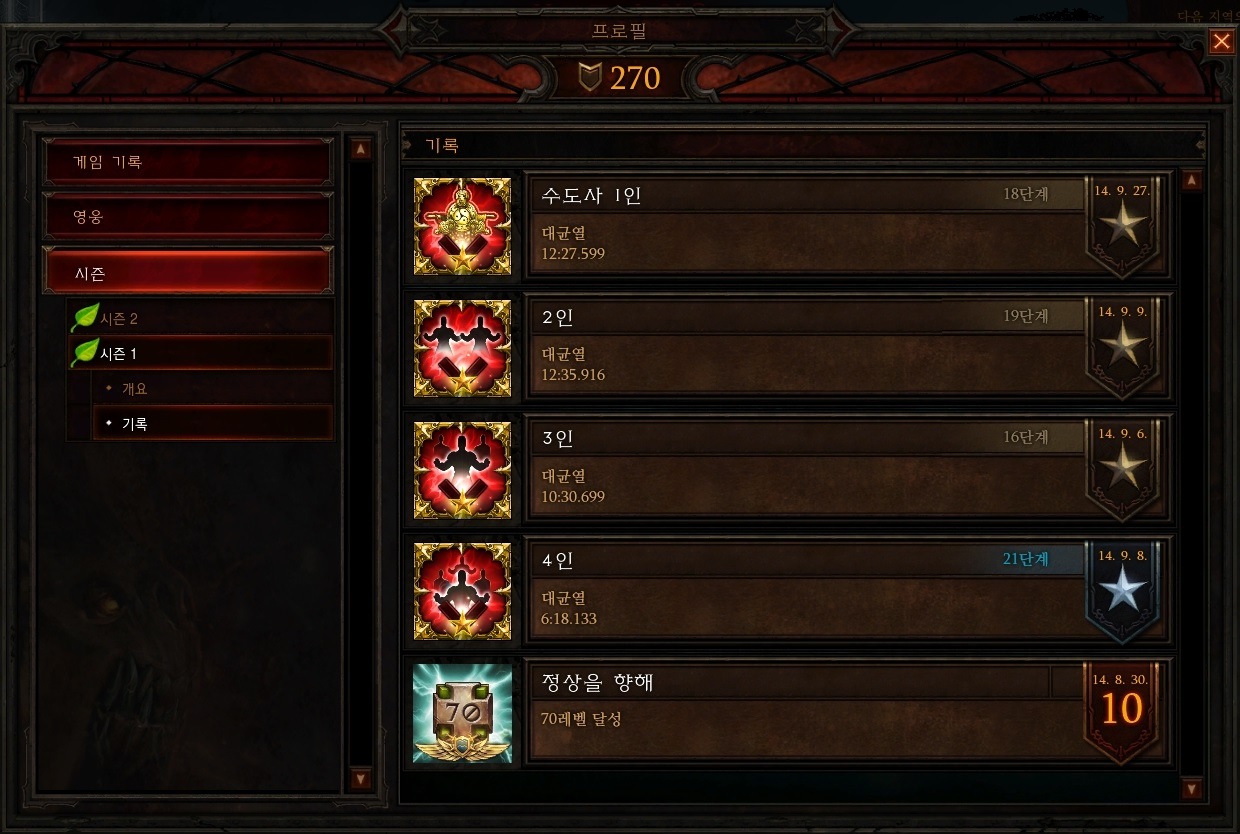
시즌 1 정벌
다른 보상과 달리, 정벌은 시즌이 종료될 때 전환되지 않는데, 그 이유는 비시즌 영웅에겐 정벌이 허용되지 않기 때문입니다. 이는 또한 시즌 중에 달성한 정벌은 비시즌 영웅들의 업적 점수에는 영향을 주지 않는 다는 의미입니다.하지만 염려하진 마세요. 시즌이 종료된 이후에도 여러분의 프로필 기록 페이지에선 언제든 여러분의 위대한 흔적을 찾아볼 수 있습니다.
시즌 1 순위표
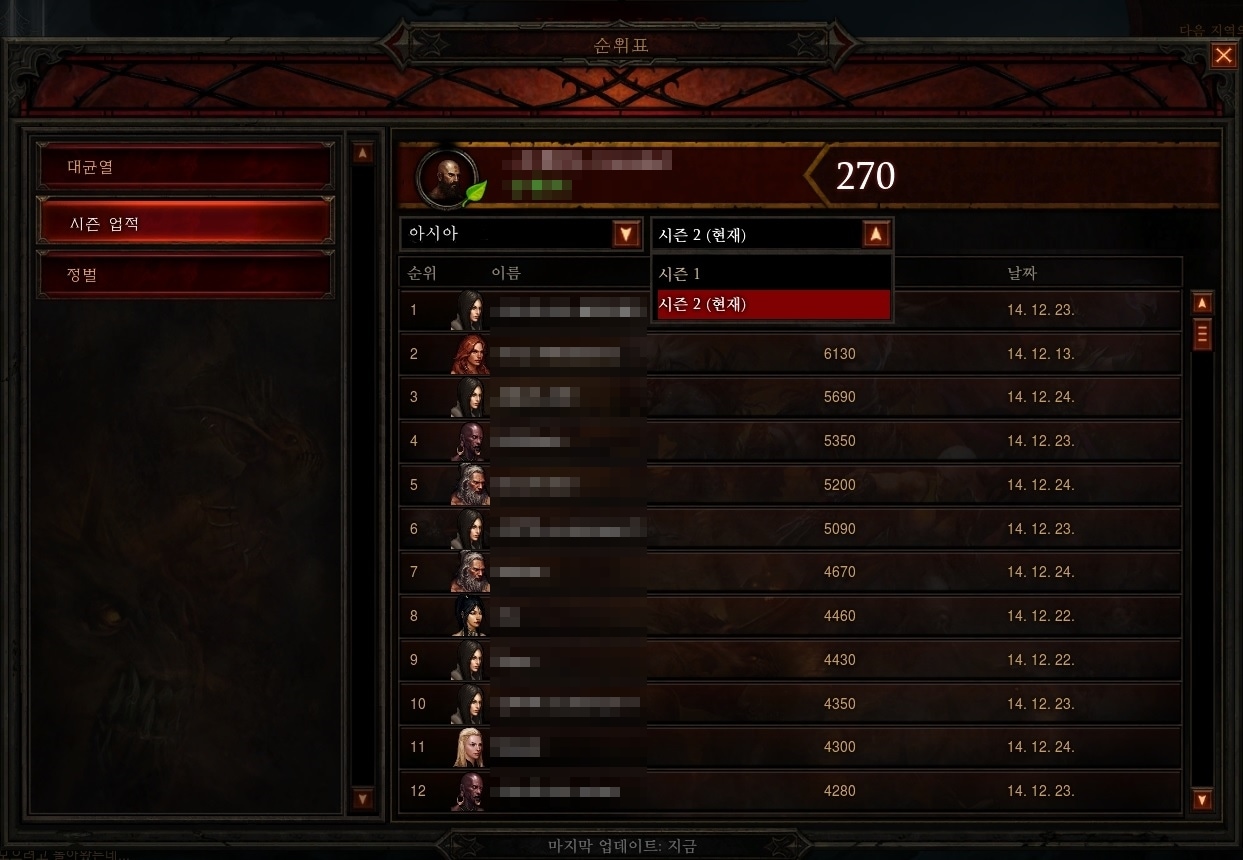
시즌이 종료되면, 모든 시즌 순위표는 초기화되고, 다음 시즌이 시작되기 전까진 새로운 순위표 기록은 제공되지 않습니다. 이전 시즌의 순위표 기록은 게임 내에서 살펴볼 수 있도록 유지됩니다. 새로운 시즌이 시작되면, 순위표의 드롭다운 메뉴를 통해 현재 시즌과 이전 시즌 기록을 오가며 확인하실 수 있습니다.물론 현재와 과거의 순위표는 이 곳 공식 홈페이지에서도 살펴보실 수 있습니다.
시즌과 시즌 사이
시즌 종료 이후 새로운 시즌이 시작되기 전까지 짧은 비시즌 기간이 존재합니다. 이 기간 중에, 여러분은 전환된 보상들과 순위표 상의 기록을 살펴보실 수 있습니다. 어쩌면 이 기간이 여러분의 성취와 전리품을 다시 살펴볼 수 있는 가장 뜻 깊은 시간이 아닐까요?그럼 언제 시즌1이 종료될까요? 현재 예상하고 있는 가장 이른 시즌 종료 일정은 2015년 2월 3일입니다. (태평양 표준시 기준이며, 정확한 일정은 추후 업데이트 예정) 예기치 못한 문제로 일정은 얼마간 미뤄질 가능성도 있지만, 저희는 최대한 이 일정에 맞춰 시즌을 종료시키려 합니다. 만약 시즌 종료 일정이 변경된다면, 업데이트된 일정을 다시 안내해 드리겠습니다.
시즌 종료를 맞이할 준비가 되셨나요?
시즌1은 어땠나요? 대균열은 몇 단계까지 가보셨나요? 정벌 임무를 몇개나 완수해보셨나요? 첫 시즌에서는 어떤 것이 제일 기억에 남나요?댓글로 여러분의 경험담이나 의견을 남겨주세요. 이제 시즌2가 얼마 남지 않았습니다.

