2016년 2월 23일 화요일
새누리당 의원, 아동 성폭력 피해자의 이름을 '총선 현수막'에 이용했다.
실제 게임중독자, 알콜중독자로 입원한 사람들을 보았는데, 그사람들 매우 착한사람들이고 정상인 사람들이더라고. 물론 우울증이나 조울증인 사람들도 마찬가지였어. 왜 입원을 한것인지 모를 정도로 정상이었어.
특이하게도 그들의 공통점은, 누구보다도 착하더라는거야. 누굴 해칠 수 있는 사람들이 아니었어.
근데 왜 게임에 빠졌을까? 왜 술을 못끊을까? 잘 모르겠더라고.
그러던 어느날, 게임중독인 아이들의 가족들을 만나게 되었고 그제서야 이유를 알겠더라.
첫번째 경우는 애를 쥐잡듯 잡는 경우 였어. 호통과 폭력이 그대로 느껴졌지.
도대체 왜저러지? 생각될 정도로 아이를 닥달하더라.
게임 계속 할꺼야? 응? 그따구로 인생 허비할꺼야? 응? 넌 대체 생각이 있는거니 없는거니?
정말 불안불안한 상황이 이어진다.
게다가 주변에 사람들이 있다면 앞다투어 아이를 핀잔주며 자신들의 입지가 옳고 아이가 틀렷으니 자신들의 자식이 좀 들어보고 느끼란 식으로 아이를 병신취급했지.
두번째 경우는 호통치거나 욕하지는 않았어. 조용했지.
두번째 경우는 호통치거나 욕하지는 않았어. 조용했지.
엄청난 중저음의 설득이 진행되더라고.
왜그러니, 게임하면 나쁜거다. 게임을 왜하니 그러지말아라 공부할 나이다. 아직도 모르겠니. 등등..
근데 이상한건 이역시도 만만찮게 긴장감 절정이라는 거야. 폭력적인 느낌은 없지만 함께 있는 것 만으로도 매우 불안해지기 시작했어.
솔직히 욕설과 폭력을 지켜보는 것과 별반 다르지 않았어.
내가 본 게임중독 아이의 부모는 게임만한다고 자기 아이를 쥐잡듯 잡거나 대놓고 병신취급 하더라는거야. 아이가 왜 게임만 하게 되었는지 물어볼 맘은 없나봐.
도박이나 게임에 빠진 아이가 있다면, 그건 행위문제나 아이문제가 아니란걸 알아야할 것 같아.
아이가 엉뚱한 행동을 한다고 폭력을 행사하거나 폭언을 일삼는건 정말 아니라고봐. 게다가 잘 타이르면 될것이라는 허울과 함께, 아이의 마음 갉아먹는 심리적 폭력을 행사하는것도 역시 아니라고 봐.
아이의 말에 귀를 기울여주는 것, 그것아 가장 어렵고도 가장 쉬운 방법이라고 생각해.
게임은 아이들에게 해만 된다고 몰아세운 당사자인, 새누리당 양천구 국회의원 예비후보 신의진이 이번엔 현수막에 성폭행 피해 아동의 이름을 써 놓고 주치의였다고 자랑하고 있는걸 보고, 괜히 울컥해서 글을쓰게되었다. 젠장.
내가 본 게임중독 아이의 부모는 게임만한다고 자기 아이를 쥐잡듯 잡거나 대놓고 병신취급 하더라는거야. 아이가 왜 게임만 하게 되었는지 물어볼 맘은 없나봐.
도박이나 게임에 빠진 아이가 있다면, 그건 행위문제나 아이문제가 아니란걸 알아야할 것 같아.
아이가 엉뚱한 행동을 한다고 폭력을 행사하거나 폭언을 일삼는건 정말 아니라고봐. 게다가 잘 타이르면 될것이라는 허울과 함께, 아이의 마음 갉아먹는 심리적 폭력을 행사하는것도 역시 아니라고 봐.
아이의 말에 귀를 기울여주는 것, 그것아 가장 어렵고도 가장 쉬운 방법이라고 생각해.
 |
| 새누리당 양천구 국회의원 예비후보 '신의진' |
게임은 아이들에게 해만 된다고 몰아세운 당사자인, 새누리당 양천구 국회의원 예비후보 신의진이 이번엔 현수막에 성폭행 피해 아동의 이름을 써 놓고 주치의였다고 자랑하고 있는걸 보고, 괜히 울컥해서 글을쓰게되었다. 젠장.
( 관련기사: http://www.huffingtonpost.kr/2016/02/22/story_n_9288018.html )
아이의 게임중독이 90%이상 부모책임 임에도, 부모의 책임이 아니고 사악한 게임과 유혹된 아이의 문제라고 둘러치는 이 인간의 주장이, 부모 입장에서 얼마나 자애로운 면죄부처럼 들리겠는가?!
이런 이중인격자 같은 인간들 때문에 정작 타인의 마음의 병을 돕고자 고생하고 노력하는 정신과 의사 분들까지 싸잡아 욕먹는거다.
 |
| 새누리당 신의진, 입후보 현수막 |
아이의 게임중독이 90%이상 부모책임 임에도, 부모의 책임이 아니고 사악한 게임과 유혹된 아이의 문제라고 둘러치는 이 인간의 주장이, 부모 입장에서 얼마나 자애로운 면죄부처럼 들리겠는가?!
"이사람아~ 아이의 맘을 좀먹는건 게임중독이 아니라 당신같은 정치중독자들 이라네.. 쯧쯧.."
이런 이중인격자 같은 인간들 때문에 정작 타인의 마음의 병을 돕고자 고생하고 노력하는 정신과 의사 분들까지 싸잡아 욕먹는거다.
C언어 CallBack 함수를 이용한 최대/최소 구하기 Example
출처: 네이버지식인
#include <stdio.h> #include <conio.h> typedef int (*CALLBACK)(int); int Callback_function(CALLBACK pCallback,int n) { return pCallback(n); } int input(int i) { int ar[10]; int j=0; int sum=0; int min=999, max=-999; for(j=0;j<i;j++){ printf("%d번의 숫자를 입력하시오 :",j+1); scanf("%d",&ar[j]); if(ar[j]<min) min=ar[j]; if(ar[j]>max) max=ar[j]; sum=sum+ar[j]; } printf("최대값은 %d, 최소값은 %d 평균은 %d입니다.\n", max,min,sum/j); return 0; } int modify(int i) { if(i>10) { printf("숫자를 다시 입력해 주세요. 10까지만 되요 :"); scanf("%d",&i); return modify(i); } else return i; } void main() { int i; printf("몇명 까지의 정보(최대값,최소값,합,평균)를 원하십니까? "); scanf("%d",&i); i=Callback_function(modify,i); Callback_function(input ,i); _getch(); }
 |
| (실행결과화면) |
2016년 2월 22일 월요일
행아웃 구글포토 공유에서 이상한 점 그리고, 앨범 희망사항
행아웃 구글포토 공유에서 이상한 점을 발견했다.
카톡에서 공유할때랑은 달리 사진수가 턱없이 부족하다.
왜지?
뭐 이상한건 이상한거고,
구글 포토가 무한대 저장이라 좋기는 한데, 공유에 있어서는 정말이지 너무 짜증난다.
최근사진 공유에만 특화된 형태랄까?
기껏 앨범을 꾸며놔도 공유에서는 사용도 못한다. 싫다. ㅠㅠ
물론 웹에서는 공유가 가능하다. 하지만 모바일에서는 그렇지 못하다.
구글제품은 어느것 하나도 빼놓지않고 너무 좋아서 이리저리 홍보하는데,
이부분은 정말 빨리 개선되었으면 하는 바램이다.
카톡에서 공유할때랑은 달리 사진수가 턱없이 부족하다.
왜지?
 |  |
| 카톡공유시 4,752건 | 행아웃 공유시 411건 |
뭐 이상한건 이상한거고,
구글 포토가 무한대 저장이라 좋기는 한데, 공유에 있어서는 정말이지 너무 짜증난다.
최근사진 공유에만 특화된 형태랄까?
기껏 앨범을 꾸며놔도 공유에서는 사용도 못한다. 싫다. ㅠㅠ
물론 웹에서는 공유가 가능하다. 하지만 모바일에서는 그렇지 못하다.
구글제품은 어느것 하나도 빼놓지않고 너무 좋아서 이리저리 홍보하는데,
이부분은 정말 빨리 개선되었으면 하는 바램이다.
2016년 2월 17일 수요일
[eBook] [10년 소장] 고수의 소통법 : 상대를 쿨하게 설득하는 실전 대화법 - 인터파크도서
출처: 인터파크도서
[eBook] [10년 소장] 고수의 소통법 : 상대를 쿨하게 설득하는 실전 대화법
고수의 소통법. 그냥 읽은만한책 없나 훝어보다가 발견한건데..
책의 목차를 보는 순간, '어? 이책 살 필요가 있나?' 라는 생각이 들어버렸다.
사실, 이 목차만으로 모든게 끝나는거 아닌가?!

(저 : 김옥림(金玉林) ㅣ 출판사 : 팬덤북스 ㅣ 발행일 : 2015년 08월26일 | 종이책 발행일 : 2015년 09월02일)
[eBook] [10년 소장] 고수의 소통법 : 상대를 쿨하게 설득하는 실전 대화법
고수의 소통법. 그냥 읽은만한책 없나 훝어보다가 발견한건데..
책의 목차를 보는 순간, '어? 이책 살 필요가 있나?' 라는 생각이 들어버렸다.
사실, 이 목차만으로 모든게 끝나는거 아닌가?!
(저 : 김옥림(金玉林) ㅣ 출판사 : 팬덤북스 ㅣ 발행일 : 2015년 08월26일 | 종이책 발행일 : 2015년 09월02일)
Chapter 1. 기분 좋게 말하는 사람 vs 기분 상하게 말하는 사람
맹목적인 비평은 사람을 죽이는 칼이다
기분 좋은 말은 오픈 마인드에서 시작된다
즐거운 커뮤니케이션의 능력을 높여라
긍정적인 말은 믿음을 주고 상대의 닫힌 마음을 열게 한다
친절은 사람을 끌어들인다
상대방의 말에 집중하는 모습을 보여라
Chapter 2. 쉽고 명쾌한 대화법 vs 장황하게 반복하는 대화법
대화는 쉽고 간결하며, 정확하고 명쾌하게
상대의 말을 즐겁게 듣는 사람이 이긴다
상대방의 입장에서 말하는 센스를 길러라
상대방이 스스로 대화를 원하도록 만들어라
목소리 톤을 밝고 경쾌하게 유지하라
Chapter 3. 감동을 주는 대화법 vs 계산이 담긴 대화법
감동은 타인에 대한 진솔한 관심에서 만들어진다
상대방의 감정에 자신을 맞추는 센스를 발휘하라
첫인상이 마지막 인상이다
말은 그 사람의 인격을 가늠하는 바이메탈bimetal이다
감성으로 상대방을 설득하라
적당한 몸동작이 마음을 움직인다
Chapter 4. 발전을 만드는 대화법 vs 신뢰를 깨뜨리는 대화법
불필요한 논쟁을 삼가라
‘YES’를 이끌어 내는 논쟁을 하라
논쟁에서는 장점을 먼저 발견하라
나의 잘못을 인정하는 것은 상대방의 마음을 사는 좋은 방법이다
논쟁을 전화위복의 기회로 만드는 대화법
논쟁 이후가 더 중요한 이유와 대처 방법
Chapter 5. 끌리는 사람의 대화법 vs 멀리하고 싶은 사람의 대화법
열심히 하는 모습에서 신뢰가 생긴다
외모로 판단하지 말고 그 사람의 중심을 보라
상대방의 자존심을 높여 주면 기쁨은 배가된다
칭찬은 소통의 묘약이다
자신만의 장점을 부각하라
Chapter 6. 상식이 통하는 대화법 vs 상식이 막히는 대화법
기본 매너를 지키면서 대화하라
유연성을 가지고 대화하라
폭넓은 상식을 길러라
상대방을 가르치려는 대화는 삼가라
상대방이 회피하며 비상식적으로 굴 때의 대처 방법
Chapter 7. 유머를 즐기는 사람 vs 유머를 부담스러워하는 사람
유머는 최상의 대화 기법이다
유머가 있는 리더십 vs 유머가 없는 리더십
누구를 만나든 즐거운 사람이 되라
유머는 삶의 흐름을 원활하게 하는 청량제이다
유머는 관용에서 오는 마음의 연금술이다
2016년 2월 16일 화요일
문의: 외장하드(Toshiba CANVIO Connect 1TB)를 갤럭시노트3 연결 시 랙이 심해지는데 왜일까요?
외장하드를 갤럭시노트3 연결 시 랙이 심해지는데 왜일까요?

- 외장하드: Toshiba CANVIO CONNECT 1TB
- 포멧방식: (파티션없이) exFAT
- OTG케이블로 연결한 스마트폰: 갤럭시 노트3
저는 외장하드에 사진, 영화, MP3, 직접만든 프로그램소스, 문서들 등을 저장합니다.
약 1년여? 잘 사용해오고 있었습니다.
처음 사용시엔 매우 우수한 성능이었습니다.
헌데 외장하드 용량이 500GB정도(?)를 넘어서면서부터는 핸드폰 연결 시 이상하게 속도저하가 발생합니다.
폴더 이동때도 버벅버벅하고 음악이나 영상재생시도 상당히 버벅댑니다.
(참고로 영화의 경우 용량은 4GB를 넘지않는 영화들입니다.)
단, PC에 연결하면 문제가 안보입니다. 정상적으로 처리됩니다.
영상재생도 정상이고 폴더 이동도 정상입니다.
그래서 핸드폰 문제인가 싶어 다른 USB를 핸드폰에 연결해 테스트해 보았으나
역시 아무 문제가 없었습니다.
요약하자면,
왜 이런 문제가 생기는걸까요?
제가 참고할만한 조언이 있을까요?
혹시 이 문제에 대해 의견있으신 분 댓글 부탁드립니다. ㅠㅠ
- 외장하드 구입시기는 10~12개월 전
- 외장하드는 파티션없이 exFAT방식으로 포멧
- 외장하드-PC 연결시 문제없음
- 외장하드-스마트폰 연결 시 속도저하 문제발생 (폴더인식 및 영상재생, 음악재생, 등등 실행시 랙 발생)
- 문제발생 시기: 하드디스크 공간이 500GB(?)정도를 넘어서면서. (현재 650GB정도 사용중)
- 스마트폰-OTG케이블을 이용한 USB연결시 속도정상 (16GB, 32GB 두종류 확인)
- 외장하드 디스크조각모음 진행해도 변화없음 (당시 5% 조각남)
- 외장하드 scandisk 결과 정상. (배드섹터 없음)
- 외장하드 연결시 스마트폰 여유공간은 11~12GB 정도
- (참고증상) 외장하드 연결 후 영상재생 시 (플레이어는 MX Player)
- 플레이어 디코더를 HW로 하면 재생시 랙 발생, 탐색 정상
- 플레이어 디코더를 SW로 하면 탐색시 랙 발생, 재생 정상
왜 이런 문제가 생기는걸까요?
제가 참고할만한 조언이 있을까요?
혹시 이 문제에 대해 의견있으신 분 댓글 부탁드립니다. ㅠㅠ
-----------------------------
2016.02.18 추가:
데이터가 많아지면서 외장하드의 성능상 차이가 나긴했던거 같긴하지만,
한가지 의구심이 들었다.
혹시 영상의 인코딩방식에도 영향이 있는건 아닐까?
모바일에 맞춰지지 않은 인코딩이라 버벅댔던것도 이유가 될 수 있지는 않을까?
나중에 인코딩을 변환해 저장해보고 차이를 봐야겠다.
외장하드를 와이파이 지원되고 무선인 것으로 새로 구매하는게 더 빠른 방법일까?
그러면 NTFS 포멧도 가능할거고.. 인터넷 데이터비도 없이 가능할거고..
윈도우에서 오라클 InstantClient 설치 후 Toad 연결법
출처: 으니's Naver Blog
윈도우에서 오라클 InstantClient 설치 후 Toad 연결법
0. 먼저 오라클 InstantClient를 다운 받는다.
http://www.oracle.com/technology/software/tech/oci/instantclient/index.html
- C:\OraClient\network 하위폴더로 admin 폴더생성
1. 압축해제 및 설치 (압축 해제경로: C:\OraClient)
- C:\OraClient 하위폴더로 network 폴더 생성- C:\OraClient\network 하위폴더로 admin 폴더생성
2. C:\OraClient\network\admin 폴더에 tnsnames.ora 파일과 sqlnet.ora 파일을 생성
- tnsnames.ora 파일내용데이터베이스명 =※ 붉은색 글씨는 환경에 맞춰 변경해 주어야 함.
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 호스트주소)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = 서비스명)
)
)
- sqlnet.ora 파일내용
SQLNET.AUTHENTICATION_SERVICES= (NTS)
NAMES.DIRECTORY_PATH= (TNSNAMES, ONAMES, HOSTNAME)
3. 제어판->시스템->고급->환경변수 선택, 사용자변수에 다음 사항 등록
PATH = %PATH%;C:\OraClient
TNS_ADMIN = C:\OraClient\network\admin
4. 레지스트리 수정
- 실행 → regedit
- HKLM > SOFTWARE 에서 마우스 오른쪽 버튼 클릭
- 새로만들기 → 키 선택
- 새 키#1로 폴더 만들어지면 이름을 Oracle로 변경
- Oracle 선택 후 오른쪽 화면에서 마우스 오른쪽 버튼을 클릭 → 새로만들기 → 문자열 값 선택
- 문자열 추가대상 항목
- NLS_LANG 생성
- 더블클릭 후 값 데이터를 Korean_Korea.KO16KSC5601 로 설정
- ORACLE_HOME 생성
- 더블클릭 후 값 데이터를 C:\OraClient로 설정
- SQLPATH 생성
- 더블클릭 후 값 데이터를 C:\OraClient로 설정
- ORACLE_SID 생성
- 더블클릭 후 값 데이터를 Ora11g로 설정
5. Toad 실행 → 접속
Oracle 테이블 및 컬럼 주석 생성
출처: DBA커뮤니티 구루비
테이블과 컬럼에 주석(Comment) 생성 방법
[2002-10-03] - 김정식 (47,592:Lv60)
37160
조회수
1
댓글수
14
COMMENT 명령으로 주석을 생성 할 수 있다. |
-- 테이블 주석 생성 SQL> COMMENT ON TABLE emp IS '사원';
-- 컬럼 주석 생성 SQL> COMMENT ON COLUMN emp.empno IS '사원번호'
테이블 및 컬럼의 주석정보 조회
USER_TAB_COMMENTS, USER_COL_COMMENTS 데이터 사전을 통해서 주석 정보를 조회 할 수 있다.-- 테이블 주석의 조회 SQL> SELECT table_name, table_type, comments FROM USER_TAB_COMMENTS WHERE comments IS NOT NULL; TABLE_NAME TABLE_TYPE COMMENTS ------------ ----------- --------- EMP TABLE 사원 -- 컬럼 주석의 조회 SQL> SELECT table_name, column_name, comments FROM USER_COL_COMMENTS WHERE comments IS NOT NULL; TABLE_NAME COLUMN_NAME COMMENTS ----------- ------------ ---------- EMP EMPNO 사원번호
주석정보 삭제
SQL> COMMENT ON COLUMN emp.empno IS '';
유니크인덱스와 PK의 차이점? - 다음팁
출처: 다음팁
Question:
PK와 유니크 인덱스의 차이점은 뭔가요?
테이블에서 FK를 사용하지 않는다면 유닉스 인덱스 만으로도 가능한데..
굳이 PK를 잡는 이유는 뭔지 알고 싶습니다.
테이블을 대표하는 것을 나타내기위해 PK를 쓴다는 말이 있는데...
이건 유닉스 인덱스로 대치 할 수 없는건가요?
PK와 유니크 인덱스 중 유니크인덱스로만 구성했을때 퍼포먼스가 더 빠르다고 하던데 맞는 말인지 알고 싶습니다. 맞다면 어떻게 해서 더 빠른지두 알고 싶습니다.
안녕하십니까? 엔코아 정보컨설팅에 근무하는 컨설턴트 조시형입니다.
우선 Primary Key와 Unique Index의 차이점을 설명하는 것은 부적절하다는 말씀을 드리고 싶습니다. 둘간의 상관관계를 설명하는 것이 맞는 개념입니다. 많은 개발자들이 PK는 왠지 부하를 준다는 잘못된 선입견을 가지고 있고 따라서 PK 대신 Unique Index를 사용하는 것으로 알고 있는데 매우 그릇된 관행(?)이라고 생각합니다. 따라서 앞에서 다른 분들이 좋은 설명 많이 해 주셨지만 부연해서 설명을 드리도록 하겠습니다.
Primary Key라고 하는 것은 논리적인 개념입니다. Primary Key는 해당 컬럼이 그 테이블의 식별자임을 나타내는 것으로서, 자신과 다른 레코드가 서로 다른 인스턴스임을 확인할 수 있게 해 주는 역할을 합니다. 즉, 해당 그 레코드의 존재자체인 것이지요.
원래 사람이름이라는 것이 '나'와 다른 사람을 식별하기 위해 사용하는 것인데, 다른 사람과 중복될 수 있으므로 나를 식별할 수 있는 속성으로서 주민등록번호라는 것을 대신 사용합니다. 따라서 주민등록번호는 나와 별개가 아닌 나의 존재 그 자체입니다. 철학적으로는 맞지 않는 설명이겠지만 적어도 ‘데이터의 세계’에서는 그렇습니다.
반면 PK constraint는 물리적인 개념입니다. "이 컬럼(들)은 다른 레코드와 구분짓는 식별자 역할을 하는 중요한 컬럼이므로 데이터는 중복을 허용해서는 안 되고(unique), null값을 허용해서도 안돼(not null)"라고 DB에게 정보를 주는 것입니다. primary key constraint를 설정하면 unique index와 not null constraint가 자동적으로 생성되는 이유도 여기에 있지요.
특히 인덱스는 PK 컬럼의 Unique성을 보장하기 위해 매우 필수적인 도구인데, 만약 인덱스 없이 해당 컬럼값이 중복되지 않도록 할 수 있는 방법을 생각해 보시기 바랍니다. 잘 떠오르지 않을 것입니다. 결론적으로 말씀드리면, 인덱스와 PK의 상관관계에 있어서 Unique이든 Non-Unique이든 Index라는 놈은 PK 컬럼의 Unique성을 보장하기 위해 사용하는 하나의 도구(Tool)에 지나지 않습니다.
어떤 의미에서만 본다면, 어느 한 컬럼에 Not Null Constraint를 주고, 그 컬럼에 Unique Index를 생성하였다면 primary key와 다를 것이 하나도 없어 보입니다. 하지만 primary key는 데이터베이스와 사용자 입장에서 매우 중요한 정보 역할을 하기 때문에 중요하다고 말씀드리고 싶습니다.
앞서 말씀드렸듯이, 원래 primary key는 “이 컬럼(들)이 테이블의 식별자(identifier)이므로 중복을 허용해서는 안 되고, null값을 허용해서도 안 된다”라는 의미론적(semantic) 인 의미에서 정의하는 것이며, DBMS는 이를 효과적으로 처리하기 위해서 index를 자동생성해서 사용하고 not null constraint를 정의하는 것입니다.
그리고 OLAP Tool과 같이 데이터베이스에 접근하는 여러 tool들이 동적으로 ad-hoc query를 생성할 때 이 정보들을 활용합니다. optimizer와 tool 입장에서 뿐만 아니라 데이터베이스를 사용하는 사용자 입장에서도 실제 document 역할을 하게 되므로 의미가 있습니다. ER Diagram을 보지 않고 data dictionary에 있는 정보만을 보고도 그 테이블의 식별자(Identifier)가 어떤 컬럼으로 구성되어 있는지 쉽게 확인할 수 있잖아요. 이런 좋은 기능과 역할을 하는데도 불구하고 unique index와 not null 만을 정의해서 primary key 기능을 대신하도록 할 이유는 없지 않을까요?
성능과 관련해서 말씀드리면, Not Null Constraint와 Unique 인덱스를 PK Constraint 대신 사용하는 것이 더 속도가 빠르다는 것은 전혀 근거없는 낭설에 불과합니다. 오히려 SQL 옵티마이저에게 더 많은 정보를 제공함으로써 더 좋은 실행계획을 만드는데 일조하게 되고 따라서 더 빨라지는 경우가 많겠지요...
2003.12.02
즉, 특정 테이블의 컬럼에 대해 Unique 인덱스가 있다고 해서, 해당 필드에 Null 값을
Insert 못하지는 않습니다. 하지만, PK Index가 설정되어 있다고 한다면 자동으로
해당 필드에 대한 Not null 제약조건이 생기기 때문에 Null을 insert할 수 없죠.
이러한 이유로 인해, SQL의 경우에 따라서는 Unique Index임에도 불구하고 Table
Access를 하는 예도 있습니다. 해당 값이 Not Null임을 보장하지 못하기 때문이죠.
따라서 SELECT문의 경우 때로는 오히려 Unique보다 PK가 아주 근소한 차이지만 더
빠른 경우도 있습니다. 물론, INSERT의 경우 제약조건에 대한 체크로 인해 조금 더
느릴(?)수도 있겠지요..
실제 테스트를 해봐도, 특정 field의 값에서 max값을 추출하고자 하는데 null이 포함되어 있으면 실제로 index search에서 찾은 값이 null인지 값을 가지고 있는지는 테이블을 뒤져봐야 알 수 있는 정보가 됩니다.
그래서 PK Index인 경우에는 (null을 가진 필드가 없음을 보장해주기 때문에..)index 영역안에서 결과 값을 리턴해줄 수 있고, Unique의 경우에는 데이터 영역까지 가서 실제 값을 확인해봐야 하는 결과가 나옵니다.
(이러한 경우도 Analyze나 테이블에 대한 정확한 통계가 있다면 그렇지 않을수도..)
이상 짧은 제 소견이였습니다.
원하시는 답변이 어느 정도 되셨는지 모르겠습니다.
행복한 하루 되시기를~~
2003.12.02
PK와 유니크 인덱스는 비교 하기엔 좀 무리가 있다고 보는데요, Table 생성시 PK에 자동적으로 유니크 인덱스가 생성 됩니다. 일반적인 유저가 생성하는 인덱스는 유닉스 인덱스로 만들지 않는것이 좋습니다.
만일 PK없이 유저가 유니크 인덱스만 만들었다고 해도 PK를 대신할수는 없습니다.
옵티마이져가 실행계획시 인덱스 안타고 FTS 하면 인덱스는 아무 소용이 없는거죠.
인덱스와 키는 개념 자체가 틀린겁니다.
테이블에서 FK를 사용 하지 않아도 PK는 필요합니다.
이유를 말하자면 모델링 측면에서는 Relational 개념에 부합하는거겠고 Database측면으로 보자면 옵티마이져가 빠른 실행계획을 만드는데 도움이 되겠죠...
굳이 따지자면 PK와 유니크키의 차이점을 물어 보시는듯 하는데요..
큰 차이점은 유니크키는 널 값을 허용 하는 겁니다. 키가 될 수 있는 후보 키가 유니크키고 그중 가장 값을 유일하게 구별해 주는 넘을 PK라고 이해하시면 될듯 합니다.
PK없이 유니크인덱스로만 구성했을때 퍼포먼스가 더 빠르냐는 문제점은 당시 테이블의 데이타의 양 및 어떤 분포도를 가지냐에 따라 사례에 따라 천차 만별 달라집니다.
Question:
유니크인덱스와 PK의 차이점?
PK와 유니크 인덱스의 차이점은 뭔가요?
테이블에서 FK를 사용하지 않는다면 유닉스 인덱스 만으로도 가능한데..
굳이 PK를 잡는 이유는 뭔지 알고 싶습니다.
테이블을 대표하는 것을 나타내기위해 PK를 쓴다는 말이 있는데...
이건 유닉스 인덱스로 대치 할 수 없는건가요?
PK와 유니크 인덱스 중 유니크인덱스로만 구성했을때 퍼포먼스가 더 빠르다고 하던데 맞는 말인지 알고 싶습니다. 맞다면 어떻게 해서 더 빠른지두 알고 싶습니다.
Answer:
안녕하십니까? 엔코아 정보컨설팅에 근무하는 컨설턴트 조시형입니다.
우선 Primary Key와 Unique Index의 차이점을 설명하는 것은 부적절하다는 말씀을 드리고 싶습니다. 둘간의 상관관계를 설명하는 것이 맞는 개념입니다. 많은 개발자들이 PK는 왠지 부하를 준다는 잘못된 선입견을 가지고 있고 따라서 PK 대신 Unique Index를 사용하는 것으로 알고 있는데 매우 그릇된 관행(?)이라고 생각합니다. 따라서 앞에서 다른 분들이 좋은 설명 많이 해 주셨지만 부연해서 설명을 드리도록 하겠습니다.
Primary Key라고 하는 것은 논리적인 개념입니다. Primary Key는 해당 컬럼이 그 테이블의 식별자임을 나타내는 것으로서, 자신과 다른 레코드가 서로 다른 인스턴스임을 확인할 수 있게 해 주는 역할을 합니다. 즉, 해당 그 레코드의 존재자체인 것이지요.
원래 사람이름이라는 것이 '나'와 다른 사람을 식별하기 위해 사용하는 것인데, 다른 사람과 중복될 수 있으므로 나를 식별할 수 있는 속성으로서 주민등록번호라는 것을 대신 사용합니다. 따라서 주민등록번호는 나와 별개가 아닌 나의 존재 그 자체입니다. 철학적으로는 맞지 않는 설명이겠지만 적어도 ‘데이터의 세계’에서는 그렇습니다.
반면 PK constraint는 물리적인 개념입니다. "이 컬럼(들)은 다른 레코드와 구분짓는 식별자 역할을 하는 중요한 컬럼이므로 데이터는 중복을 허용해서는 안 되고(unique), null값을 허용해서도 안돼(not null)"라고 DB에게 정보를 주는 것입니다. primary key constraint를 설정하면 unique index와 not null constraint가 자동적으로 생성되는 이유도 여기에 있지요.
특히 인덱스는 PK 컬럼의 Unique성을 보장하기 위해 매우 필수적인 도구인데, 만약 인덱스 없이 해당 컬럼값이 중복되지 않도록 할 수 있는 방법을 생각해 보시기 바랍니다. 잘 떠오르지 않을 것입니다. 결론적으로 말씀드리면, 인덱스와 PK의 상관관계에 있어서 Unique이든 Non-Unique이든 Index라는 놈은 PK 컬럼의 Unique성을 보장하기 위해 사용하는 하나의 도구(Tool)에 지나지 않습니다.
어떤 의미에서만 본다면, 어느 한 컬럼에 Not Null Constraint를 주고, 그 컬럼에 Unique Index를 생성하였다면 primary key와 다를 것이 하나도 없어 보입니다. 하지만 primary key는 데이터베이스와 사용자 입장에서 매우 중요한 정보 역할을 하기 때문에 중요하다고 말씀드리고 싶습니다.
앞서 말씀드렸듯이, 원래 primary key는 “이 컬럼(들)이 테이블의 식별자(identifier)이므로 중복을 허용해서는 안 되고, null값을 허용해서도 안 된다”라는 의미론적(semantic) 인 의미에서 정의하는 것이며, DBMS는 이를 효과적으로 처리하기 위해서 index를 자동생성해서 사용하고 not null constraint를 정의하는 것입니다.
참고로 primary key를 위해서 반드시 unique index가 필요한 것은 아닙니다. non-unique index만 있더라도 새로운 값이 들어올 때 중복값이 있는지 체크하는 데에는 전혀 문제가 없으므로 기존에 이미 non-unique 인덱스가 정의되어 있는 상황이었다면 그 인덱스를 그대로 사용합니다. DW 시스템에서 대량의 데이터 로딩시 속도를 빠르게 하기 위해 PK Constraint를 일시적으로 Disable 시키는 경우가 있는데 이렇게 되면 Unique Index도 동시에 제거되므로 인덱스를 다시 생성해야 하는 부담이 생깁니다. 이러한 부담을 덜기 위해 의도적으로 non-unique index를 생성하는 경우가 있는데 이에 대해서는 더 깊이 언급하지 않겠습니다.
하여튼 primary key, foreign key, not null 등과 같은 integrity constraint 정보들은 plan을 생성하고, query rewrite(주로 DW에서 많이 사용되는 기능임)를 수행할 때, 그리고 기타 여러가지 용도로 데이터베이스에 의해 사용되어집니다.
하여튼 primary key, foreign key, not null 등과 같은 integrity constraint 정보들은 plan을 생성하고, query rewrite(주로 DW에서 많이 사용되는 기능임)를 수행할 때, 그리고 기타 여러가지 용도로 데이터베이스에 의해 사용되어집니다.
그리고 OLAP Tool과 같이 데이터베이스에 접근하는 여러 tool들이 동적으로 ad-hoc query를 생성할 때 이 정보들을 활용합니다. optimizer와 tool 입장에서 뿐만 아니라 데이터베이스를 사용하는 사용자 입장에서도 실제 document 역할을 하게 되므로 의미가 있습니다. ER Diagram을 보지 않고 data dictionary에 있는 정보만을 보고도 그 테이블의 식별자(Identifier)가 어떤 컬럼으로 구성되어 있는지 쉽게 확인할 수 있잖아요. 이런 좋은 기능과 역할을 하는데도 불구하고 unique index와 not null 만을 정의해서 primary key 기능을 대신하도록 할 이유는 없지 않을까요?
성능과 관련해서 말씀드리면, Not Null Constraint와 Unique 인덱스를 PK Constraint 대신 사용하는 것이 더 속도가 빠르다는 것은 전혀 근거없는 낭설에 불과합니다. 오히려 SQL 옵티마이저에게 더 많은 정보를 제공함으로써 더 좋은 실행계획을 만드는데 일조하게 되고 따라서 더 빨라지는 경우가 많겠지요...
2003.12.02
음.. 좋은 글 잘읽고 갑니다..
그리구요..
PK와 유니크 인덱스 중에서 유니크 인덱스가 퍼포먼스가 빠르다는 말은요..
아마두 이런 경우가 아닐까 생각이 됩니다..
일단 위에서도 말씀 하셨드시 유니크 인덱스는 null 값을 입력 할수 있습니다.
즉 index를 생성하고 scan 할때 null에 대해서는 index를 만들지 않기 때문에 더 빠르다는 말이 나오지 않았을까 생각이 되는군요..
예로 어떤 특정 값을 입력할때 defalut value로 '9999999'이런 값이 들어 가는 것과 그냥 null이 들어 갈 경우, '9999999'인 경우를 많이 select하지 않는다면 디폴터로 특정 값을 넣지 않는 경우와 유사하죠..
null을 빼고 index를 구성하니까 당연히 빠르죠..
이상.. 주제와는 좀 벗어난듯 하네요.. 지송..
2003.12.02
안녕하세요.. 이노입니다.
궁금해하시는 내용에 대한 답변은 예전 좀 다른 문제로 제가 답변을 올렸던 경우와
유사한 듯 하여 그때 내용을 간략하게 다시 올리겠습니다.
먼저 PK Index와 Unique Index의 차이는 간단하게 Nullable의 차이라고 하겠습니다.
쉽게 말해서 PK Index라는 것은 Unique Index + Not Null을 의미합니다.
반대로 Unique Index는 인덱스가 걸리는 필드에 대해서도 Null을 허용하죠.
그리구요..
PK와 유니크 인덱스 중에서 유니크 인덱스가 퍼포먼스가 빠르다는 말은요..
아마두 이런 경우가 아닐까 생각이 됩니다..
일단 위에서도 말씀 하셨드시 유니크 인덱스는 null 값을 입력 할수 있습니다.
즉 index를 생성하고 scan 할때 null에 대해서는 index를 만들지 않기 때문에 더 빠르다는 말이 나오지 않았을까 생각이 되는군요..
예로 어떤 특정 값을 입력할때 defalut value로 '9999999'이런 값이 들어 가는 것과 그냥 null이 들어 갈 경우, '9999999'인 경우를 많이 select하지 않는다면 디폴터로 특정 값을 넣지 않는 경우와 유사하죠..
null을 빼고 index를 구성하니까 당연히 빠르죠..
이상.. 주제와는 좀 벗어난듯 하네요.. 지송..
2003.12.02
안녕하세요.. 이노입니다.
궁금해하시는 내용에 대한 답변은 예전 좀 다른 문제로 제가 답변을 올렸던 경우와
유사한 듯 하여 그때 내용을 간략하게 다시 올리겠습니다.
먼저 PK Index와 Unique Index의 차이는 간단하게 Nullable의 차이라고 하겠습니다.
쉽게 말해서 PK Index라는 것은 Unique Index + Not Null을 의미합니다.
반대로 Unique Index는 인덱스가 걸리는 필드에 대해서도 Null을 허용하죠.
즉, 특정 테이블의 컬럼에 대해 Unique 인덱스가 있다고 해서, 해당 필드에 Null 값을
Insert 못하지는 않습니다. 하지만, PK Index가 설정되어 있다고 한다면 자동으로
해당 필드에 대한 Not null 제약조건이 생기기 때문에 Null을 insert할 수 없죠.
이러한 이유로 인해, SQL의 경우에 따라서는 Unique Index임에도 불구하고 Table
Access를 하는 예도 있습니다. 해당 값이 Not Null임을 보장하지 못하기 때문이죠.
따라서 SELECT문의 경우 때로는 오히려 Unique보다 PK가 아주 근소한 차이지만 더
빠른 경우도 있습니다. 물론, INSERT의 경우 제약조건에 대한 체크로 인해 조금 더
느릴(?)수도 있겠지요..
실제 테스트를 해봐도, 특정 field의 값에서 max값을 추출하고자 하는데 null이 포함되어 있으면 실제로 index search에서 찾은 값이 null인지 값을 가지고 있는지는 테이블을 뒤져봐야 알 수 있는 정보가 됩니다.
그래서 PK Index인 경우에는 (null을 가진 필드가 없음을 보장해주기 때문에..)index 영역안에서 결과 값을 리턴해줄 수 있고, Unique의 경우에는 데이터 영역까지 가서 실제 값을 확인해봐야 하는 결과가 나옵니다.
(이러한 경우도 Analyze나 테이블에 대한 정확한 통계가 있다면 그렇지 않을수도..)
이상 짧은 제 소견이였습니다.
원하시는 답변이 어느 정도 되셨는지 모르겠습니다.
행복한 하루 되시기를~~
2003.12.02
PK와 유니크 인덱스는 비교 하기엔 좀 무리가 있다고 보는데요, Table 생성시 PK에 자동적으로 유니크 인덱스가 생성 됩니다. 일반적인 유저가 생성하는 인덱스는 유닉스 인덱스로 만들지 않는것이 좋습니다.
만일 PK없이 유저가 유니크 인덱스만 만들었다고 해도 PK를 대신할수는 없습니다.
옵티마이져가 실행계획시 인덱스 안타고 FTS 하면 인덱스는 아무 소용이 없는거죠.
인덱스와 키는 개념 자체가 틀린겁니다.
테이블에서 FK를 사용 하지 않아도 PK는 필요합니다.
이유를 말하자면 모델링 측면에서는 Relational 개념에 부합하는거겠고 Database측면으로 보자면 옵티마이져가 빠른 실행계획을 만드는데 도움이 되겠죠...
굳이 따지자면 PK와 유니크키의 차이점을 물어 보시는듯 하는데요..
큰 차이점은 유니크키는 널 값을 허용 하는 겁니다. 키가 될 수 있는 후보 키가 유니크키고 그중 가장 값을 유일하게 구별해 주는 넘을 PK라고 이해하시면 될듯 합니다.
PK없이 유니크인덱스로만 구성했을때 퍼포먼스가 더 빠르냐는 문제점은 당시 테이블의 데이타의 양 및 어떤 분포도를 가지냐에 따라 사례에 따라 천차 만별 달라집니다.
2016년 2월 11일 목요일
힉스 입자를 쉬운 그림으로 설명한 뉴욕타임즈 기사 - ㅍㅍㅅㅅ
원문: ㅍㅍㅅㅅ ( http://ppss.kr/archives/14642 )
2013년 10월 16일 by 썬도그
힉스 입자는 신의 입자라고 합니다. 하지만 그 힉스 입자가 정확하게 왜 신의 입자인지 아는 분은 많지 않습니다. 저도 어렴풋이 알고는 있습니다만 큰 관심은 없고, 원자를 쪼개면 나오는 입자 정도로만 알고 있습니다.
그런데 그 동안 이론으로만 존재하고 있던 힉스 입자가 실존하는 물질임이 밝혀졌고, 얼마 후에 힉스 입자의 존재를 예언한 피터 힉스 박사가 2013년 노벨 물리학상을 수상 했습니다. 많은 사람들이 힉스 입자에 대한 이야기를 하지만 쉽게 설명한 것은 거의 없더군요. 그런데 뉴욕 타임즈가 일반인도 쉽게 이해할 수 있는 힉스 입자에 대한 설명을 도식화 한 이미지로 소개 했습니다. 기사 내용을 힉스 입자에 대한 궁금증이 있는 분들을 위해서 소개 합니다.
(아래)
힉스 입자란 무엇일까?
 힉스 입자란 무엇일까?
힉스 입자란 무엇일까?
 힉스 장이란 무엇일까?
힉스 장이란 무엇일까?
 힉스 입자는 눈에 보이지 않기 때문에 많은 사람들이 이 힉스 입자를 설명 할 때 다른 것에 비유해서 설명합니다.
힉스 입자는 눈에 보이지 않기 때문에 많은 사람들이 이 힉스 입자를 설명 할 때 다른 것에 비유해서 설명합니다.
 힉스 입자는 공간을 통과해서 물건을 당기는 성질, 즉 중력의 특징이 있기 때문에 흔히 우주 당밀(끈적끈적한 설탕)로 묘사합니다.
힉스 입자는 공간을 통과해서 물건을 당기는 성질, 즉 중력의 특징이 있기 때문에 흔히 우주 당밀(끈적끈적한 설탕)로 묘사합니다.
 그러나 이번에는 눈으로 힉스 입자를 설명해 보겠습니다.
그러나 이번에는 눈으로 힉스 입자를 설명해 보겠습니다.
 스키를 타는 사람은 스키가 없는 사람 보다 저항을 받지 않고 눈 위를 질주 할 수 있습니다.
스키를 타는 사람은 스키가 없는 사람 보다 저항을 받지 않고 눈 위를 질주 할 수 있습니다.
 스노우 슈즈를 신은 여자분도 눈에 빠지지 않고 걸을 수 있지만, 좀 느리겠죠.
스노우 슈즈를 신은 여자분도 눈에 빠지지 않고 걸을 수 있지만, 좀 느리겠죠.
 무거운 부츠를 신은 남자도 매 걸음 걸음 마다 터벅 터벅 힘겹게 눈 위를 걷게 됩니다.
무거운 부츠를 신은 남자도 매 걸음 걸음 마다 터벅 터벅 힘겹게 눈 위를 걷게 됩니다.
 그러나 하늘을 나는 새는 눈에 빠지지 않기 때문에 눈이 오던 안 오던 빠르게 날 수 있습니다. 쌓인 눈과 직접적으로 접촉하지 않기 때문입니다.
그러나 하늘을 나는 새는 눈에 빠지지 않기 때문에 눈이 오던 안 오던 빠르게 날 수 있습니다. 쌓인 눈과 직접적으로 접촉하지 않기 때문입니다.

 하늘에서 내리는 눈은 힉스 입자이고 눈이 내려서 쌓인 눈은 힉스 장(필드)와 비슷합니다.
하늘에서 내리는 눈은 힉스 입자이고 눈이 내려서 쌓인 눈은 힉스 장(필드)와 비슷합니다.
 힉스 장과 상호 작용하는 물체는 질량을 자기게 됩니다.
힉스 장과 상호 작용하는 물체는 질량을 자기게 됩니다.
 스키어는 내린 눈 위를 빠르게 질주 할 수 있습니다. 이 스키어는 전자입니다. 전자는 힉스 장(쌓인 눈)위를 아주 빠르게 질주하는데 빠르게 질주하면 적은 질량을 얻게 됩니다.
스키어는 내린 눈 위를 빠르게 질주 할 수 있습니다. 이 스키어는 전자입니다. 전자는 힉스 장(쌓인 눈)위를 아주 빠르게 질주하는데 빠르게 질주하면 적은 질량을 얻게 됩니다.
 양성자와 중성자를 만드는 쿼크는 스노우부츠를 신은 여자분과 같습니다. 그냥 일반 부츠보다는 눈에 빠지지 않고 눈 위를 걸을 수 있지만 스키어보다는 느리기 때문에 큰 질량을 갖게 됩니다.
양성자와 중성자를 만드는 쿼크는 스노우부츠를 신은 여자분과 같습니다. 그냥 일반 부츠보다는 눈에 빠지지 않고 눈 위를 걸을 수 있지만 스키어보다는 느리기 때문에 큰 질량을 갖게 됩니다.
 W보손과 Z보손은 쌓인 눈(힉스 장)길을 무거운 부츠를 신고 걷는 사람으로 수천 배나 큰 질량을 갖게 됩니다.
W보손과 Z보손은 쌓인 눈(힉스 장)길을 무거운 부츠를 신고 걷는 사람으로 수천 배나 큰 질량을 갖게 됩니다.

 광자(포톤)과 글루온(중성자를 이루는 쿼크를 묶는 글루 같은 역할을 하는 소립자) 는 눈 위를 나는 새와 같이 쌓인 눈에 접촉하지 않기 때문에 빠르게 날 수 있으며 때문에 질량이 없습니다.
광자(포톤)과 글루온(중성자를 이루는 쿼크를 묶는 글루 같은 역할을 하는 소립자) 는 눈 위를 나는 새와 같이 쌓인 눈에 접촉하지 않기 때문에 빠르게 날 수 있으며 때문에 질량이 없습니다.
 50년 전, 물리학에서는 왜 질량이 있는 물질과 질량이 없는 물질이 존재하는지 알 수 없었습니다.
50년 전, 물리학에서는 왜 질량이 있는 물질과 질량이 없는 물질이 존재하는지 알 수 없었습니다.
 그래서 나온 이론이 바로 힉스 입자입니다. 즉, 질량에 관여하는 뭔가가 있다고 생각한 것이죠.
그래서 나온 이론이 바로 힉스 입자입니다. 즉, 질량에 관여하는 뭔가가 있다고 생각한 것이죠.
 힉스 입자는 하늘에서 춤추듯 내려오는 눈송이처럼 사라지고 쉽게 잃어버리기 쉽습니다.
힉스 입자는 하늘에서 춤추듯 내려오는 눈송이처럼 사라지고 쉽게 잃어버리기 쉽습니다.
 이후, 힉스 입자에 대한 연구가 시작 되었습니다.
이후, 힉스 입자에 대한 연구가 시작 되었습니다.
 힉스 입자 연구는 직접 눈으로 보지 못한 눈송이 같았습니다.
힉스 입자 연구는 직접 눈으로 보지 못한 눈송이 같았습니다.
 그러나 지금 녹은 눈 속에서 아주 조금 형태가 남아 있는 눈 결정을 발견합니다.
그러나 지금 녹은 눈 속에서 아주 조금 형태가 남아 있는 눈 결정을 발견합니다.
 힉스 입자는 눈으로 볼 수 없습니다.
힉스 입자는 눈으로 볼 수 없습니다.
 또한, 힉스 장과 힉스 입자를 감지할 센서도 아직까지는 없습니다.
또한, 힉스 장과 힉스 입자를 감지할 센서도 아직까지는 없습니다.
 50년 동안 물리학자들은 더 크고 강력한 입자 가속기를 개발해 왔습니다.
50년 동안 물리학자들은 더 크고 강력한 입자 가속기를 개발해 왔습니다.
 CERN(유럽입자물리연구소)에는 세계에서 가장 큰 입자 가속기가 있습니다. 이 입자 가속기에서 양성자를 빛의 속도까지 가속시킵니다.
CERN(유럽입자물리연구소)에는 세계에서 가장 큰 입자 가속기가 있습니다. 이 입자 가속기에서 양성자를 빛의 속도까지 가속시킵니다.
 그리고 양성자끼리 충돌 시켜서 폭발시킵니다. 양성자는 소멸하는 대신에 엄청난 에너지가 방출됩니다.
그리고 양성자끼리 충돌 시켜서 폭발시킵니다. 양성자는 소멸하는 대신에 엄청난 에너지가 방출됩니다.
 아인슈타인은 질량은 에너지라고 하는 저 유명한 공식은 E=MC2를 세상에 선보였습니다. 또한, 에너지는 파괴되지 않는다고 말하고 있습니다.
아인슈타인은 질량은 에너지라고 하는 저 유명한 공식은 E=MC2를 세상에 선보였습니다. 또한, 에너지는 파괴되지 않는다고 말하고 있습니다.
 양성자끼리의 충돌은 에너지를 방출하고 작은 질량의 변화를 가져옵니다. 그리고 많은 새로운 입자가 생겨납니다.
양성자끼리의 충돌은 에너지를 방출하고 작은 질량의 변화를 가져옵니다. 그리고 많은 새로운 입자가 생겨납니다.
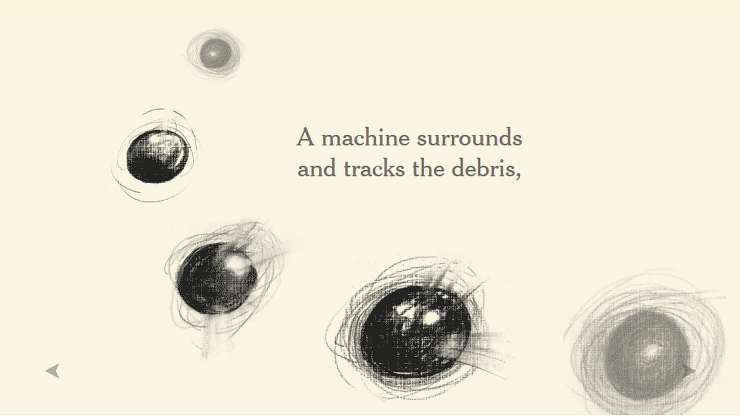 CERN의 가속기는 하전 입자(전기적 특징을 가진 입자, 전자, 양성자)를 가속시켜서 충돌시킵니다.
CERN의 가속기는 하전 입자(전기적 특징을 가진 입자, 전자, 양성자)를 가속시켜서 충돌시킵니다.
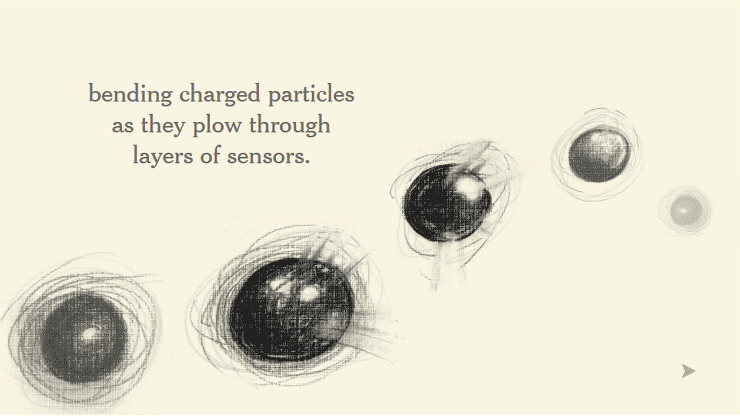
 초당 수백만 번, 또는 수천 만 번 계속 충돌시킵니다.
초당 수백만 번, 또는 수천 만 번 계속 충돌시킵니다.
 그 이유는 무언가가 일어날 것을 목격하는 것은 매우 드문 일이기 때문입니다.
그 이유는 무언가가 일어날 것을 목격하는 것은 매우 드문 일이기 때문입니다.
 수십억 번의 충돌 중 단 한 번만 힉스 입자가 모습을 보였습니다.
수십억 번의 충돌 중 단 한 번만 힉스 입자가 모습을 보였습니다.

 하지만 그 순간을 직접 센서가 감지할 수 없었습니다. 아직 샴페인을 터트리는 것을 용인하지 않네요.
하지만 그 순간을 직접 센서가 감지할 수 없었습니다. 아직 샴페인을 터트리는 것을 용인하지 않네요.
 힉스 입자는 불안정하고 즉시 분열합니다.
힉스 입자는 불안정하고 즉시 분열합니다.
 하전입자 충돌을 수조 번을 충돌한 후에 힉스 입자의 흔적이 통계적으로 나올 확율이 높기에 수 조번의 하전입자를 충돌시켰습니다.
하전입자 충돌을 수조 번을 충돌한 후에 힉스 입자의 흔적이 통계적으로 나올 확율이 높기에 수 조번의 하전입자를 충돌시켰습니다.
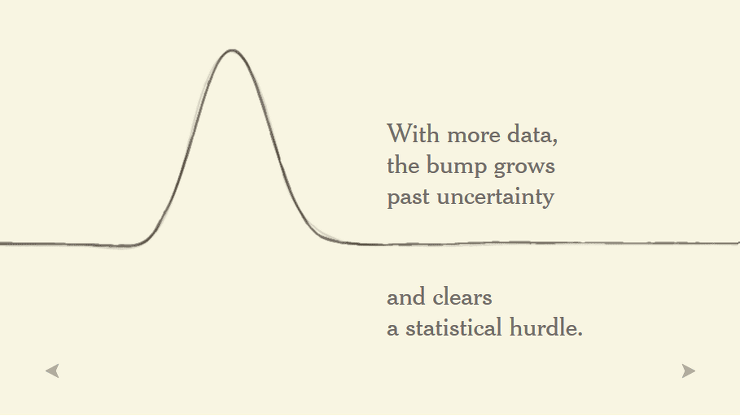 그리고 얼마 전에 지금까지 그 존재가 확인되지 않았던 힉스 입자에 대한 존재가 유의미한 데이터로 확인이 되었습니다.
그리고 얼마 전에 지금까지 그 존재가 확인되지 않았던 힉스 입자에 대한 존재가 유의미한 데이터로 확인이 되었습니다.

 피터 힉스 박사는 이 힉스 입자 존재 확인으로 노벨 물리학상을 받게 됩니다.
피터 힉스 박사는 이 힉스 입자 존재 확인으로 노벨 물리학상을 받게 됩니다.
이론이 현실이 되었네요. 힉스 입자는 중력에 관한 입자이기 때문에 이걸 인간이 콘트럴 할 수 있게 된다면 솜털 보다 가벼운 강철을 만들 수 있다고 하네요. 힉스 입자에 대한 내용은 네이버캐스트에서도 읽을 수 있습니다.
2013년 10월 16일 by 썬도그
힉스 입자를 쉬운 그림으로 설명한 뉴욕타임즈 기사
힉스 입자는 신의 입자라고 합니다. 하지만 그 힉스 입자가 정확하게 왜 신의 입자인지 아는 분은 많지 않습니다. 저도 어렴풋이 알고는 있습니다만 큰 관심은 없고, 원자를 쪼개면 나오는 입자 정도로만 알고 있습니다.
그런데 그 동안 이론으로만 존재하고 있던 힉스 입자가 실존하는 물질임이 밝혀졌고, 얼마 후에 힉스 입자의 존재를 예언한 피터 힉스 박사가 2013년 노벨 물리학상을 수상 했습니다. 많은 사람들이 힉스 입자에 대한 이야기를 하지만 쉽게 설명한 것은 거의 없더군요. 그런데 뉴욕 타임즈가 일반인도 쉽게 이해할 수 있는 힉스 입자에 대한 설명을 도식화 한 이미지로 소개 했습니다. 기사 내용을 힉스 입자에 대한 궁금증이 있는 분들을 위해서 소개 합니다.
(아래)
힉스 입자란 무엇일까?
힉스 입자란 무엇일까?힉스 장이란 무엇일까?힉스 입자는 눈에 보이지 않기 때문에 많은 사람들이 이 힉스 입자를 설명 할 때 다른 것에 비유해서 설명합니다.힉스 입자는 공간을 통과해서 물건을 당기는 성질, 즉 중력의 특징이 있기 때문에 흔히 우주 당밀(끈적끈적한 설탕)로 묘사합니다.그러나 이번에는 눈으로 힉스 입자를 설명해 보겠습니다.스키를 타는 사람은 스키가 없는 사람 보다 저항을 받지 않고 눈 위를 질주 할 수 있습니다.스노우 슈즈를 신은 여자분도 눈에 빠지지 않고 걸을 수 있지만, 좀 느리겠죠.무거운 부츠를 신은 남자도 매 걸음 걸음 마다 터벅 터벅 힘겹게 눈 위를 걷게 됩니다.그러나 하늘을 나는 새는 눈에 빠지지 않기 때문에 눈이 오던 안 오던 빠르게 날 수 있습니다. 쌓인 눈과 직접적으로 접촉하지 않기 때문입니다.하늘에서 내리는 눈은 힉스 입자이고 눈이 내려서 쌓인 눈은 힉스 장(필드)와 비슷합니다.힉스 장과 상호 작용하는 물체는 질량을 자기게 됩니다.스키어는 내린 눈 위를 빠르게 질주 할 수 있습니다. 이 스키어는 전자입니다. 전자는 힉스 장(쌓인 눈)위를 아주 빠르게 질주하는데 빠르게 질주하면 적은 질량을 얻게 됩니다.양성자와 중성자를 만드는 쿼크는 스노우부츠를 신은 여자분과 같습니다. 그냥 일반 부츠보다는 눈에 빠지지 않고 눈 위를 걸을 수 있지만 스키어보다는 느리기 때문에 큰 질량을 갖게 됩니다.W보손과 Z보손은 쌓인 눈(힉스 장)길을 무거운 부츠를 신고 걷는 사람으로 수천 배나 큰 질량을 갖게 됩니다.광자(포톤)과 글루온(중성자를 이루는 쿼크를 묶는 글루 같은 역할을 하는 소립자) 는 눈 위를 나는 새와 같이 쌓인 눈에 접촉하지 않기 때문에 빠르게 날 수 있으며 때문에 질량이 없습니다.50년 전, 물리학에서는 왜 질량이 있는 물질과 질량이 없는 물질이 존재하는지 알 수 없었습니다.그래서 나온 이론이 바로 힉스 입자입니다. 즉, 질량에 관여하는 뭔가가 있다고 생각한 것이죠.힉스 입자는 하늘에서 춤추듯 내려오는 눈송이처럼 사라지고 쉽게 잃어버리기 쉽습니다.이후, 힉스 입자에 대한 연구가 시작 되었습니다.힉스 입자 연구는 직접 눈으로 보지 못한 눈송이 같았습니다.그러나 지금 녹은 눈 속에서 아주 조금 형태가 남아 있는 눈 결정을 발견합니다.힉스 입자는 눈으로 볼 수 없습니다.또한, 힉스 장과 힉스 입자를 감지할 센서도 아직까지는 없습니다.50년 동안 물리학자들은 더 크고 강력한 입자 가속기를 개발해 왔습니다.CERN(유럽입자물리연구소)에는 세계에서 가장 큰 입자 가속기가 있습니다. 이 입자 가속기에서 양성자를 빛의 속도까지 가속시킵니다.그리고 양성자끼리 충돌 시켜서 폭발시킵니다. 양성자는 소멸하는 대신에 엄청난 에너지가 방출됩니다.아인슈타인은 질량은 에너지라고 하는 저 유명한 공식은 E=MC2를 세상에 선보였습니다. 또한, 에너지는 파괴되지 않는다고 말하고 있습니다.양성자끼리의 충돌은 에너지를 방출하고 작은 질량의 변화를 가져옵니다. 그리고 많은 새로운 입자가 생겨납니다.CERN의 가속기는 하전 입자(전기적 특징을 가진 입자, 전자, 양성자)를 가속시켜서 충돌시킵니다.초당 수백만 번, 또는 수천 만 번 계속 충돌시킵니다.그 이유는 무언가가 일어날 것을 목격하는 것은 매우 드문 일이기 때문입니다.수십억 번의 충돌 중 단 한 번만 힉스 입자가 모습을 보였습니다.하지만 그 순간을 직접 센서가 감지할 수 없었습니다. 아직 샴페인을 터트리는 것을 용인하지 않네요.힉스 입자는 불안정하고 즉시 분열합니다.하전입자 충돌을 수조 번을 충돌한 후에 힉스 입자의 흔적이 통계적으로 나올 확율이 높기에 수 조번의 하전입자를 충돌시켰습니다.그리고 얼마 전에 지금까지 그 존재가 확인되지 않았던 힉스 입자에 대한 존재가 유의미한 데이터로 확인이 되었습니다.피터 힉스 박사는 이 힉스 입자 존재 확인으로 노벨 물리학상을 받게 됩니다.이론이 현실이 되었네요. 힉스 입자는 중력에 관한 입자이기 때문에 이걸 인간이 콘트럴 할 수 있게 된다면 솜털 보다 가벼운 강철을 만들 수 있다고 하네요. 힉스 입자에 대한 내용은 네이버캐스트에서도 읽을 수 있습니다.
피드 구독하기:
글 (Atom)
-
mecab-ko-dic 품사 태그 설명 대분류 세종 품사 태그 mecab-ko-dic 품사 태그 태그 설명 태그 설명 체언 NNG 일반 명사 NNG 일반 명사 NNP 고유 명사 NNP 고유 명사 NNB 의존 명사 NNB 의존 명사 ...
-
 mecab-ko-dic 사전관리 Mecab-ko-dic 사전은 아주 간편한 몇가지 규칙으로 관리된다. 비전문가라 하여도 다른 형태소분석기에 비해, 간단하게 배우고 관리할 수 있다는 장점이 있다. (사전 설치/추가 방법은 본 포스트 하단참고)...
mecab-ko-dic 사전관리 Mecab-ko-dic 사전은 아주 간편한 몇가지 규칙으로 관리된다. 비전문가라 하여도 다른 형태소분석기에 비해, 간단하게 배우고 관리할 수 있다는 장점이 있다. (사전 설치/추가 방법은 본 포스트 하단참고)... -
CentOS 7.x 에서의 Port 관리법 개요 포트를 오픈하려고 iptables 명령을 사용했다. 그런데 아무런 반응이 없었다. iptables -I INPUT -p tcp --dport 8889 -j ACCEPT ...
